数据结构之并查集
[toc]
并查集基础
概念及其介绍
并查集是一种树型结构,用于处理一些不相交集合的合并及查询问题。 并查集的思想是用一个数组表示了整片森林(parent),树的根节点唯一标识了一个集合,我们只要找到了某个元素的的树根,就能确定它在哪个集合里。 对于并查集主要支持两个操作:
- 并{ union(p,q) }
- 查找{ find(p) } 来回答一个问题:
连接{ inConnected(p, q) }
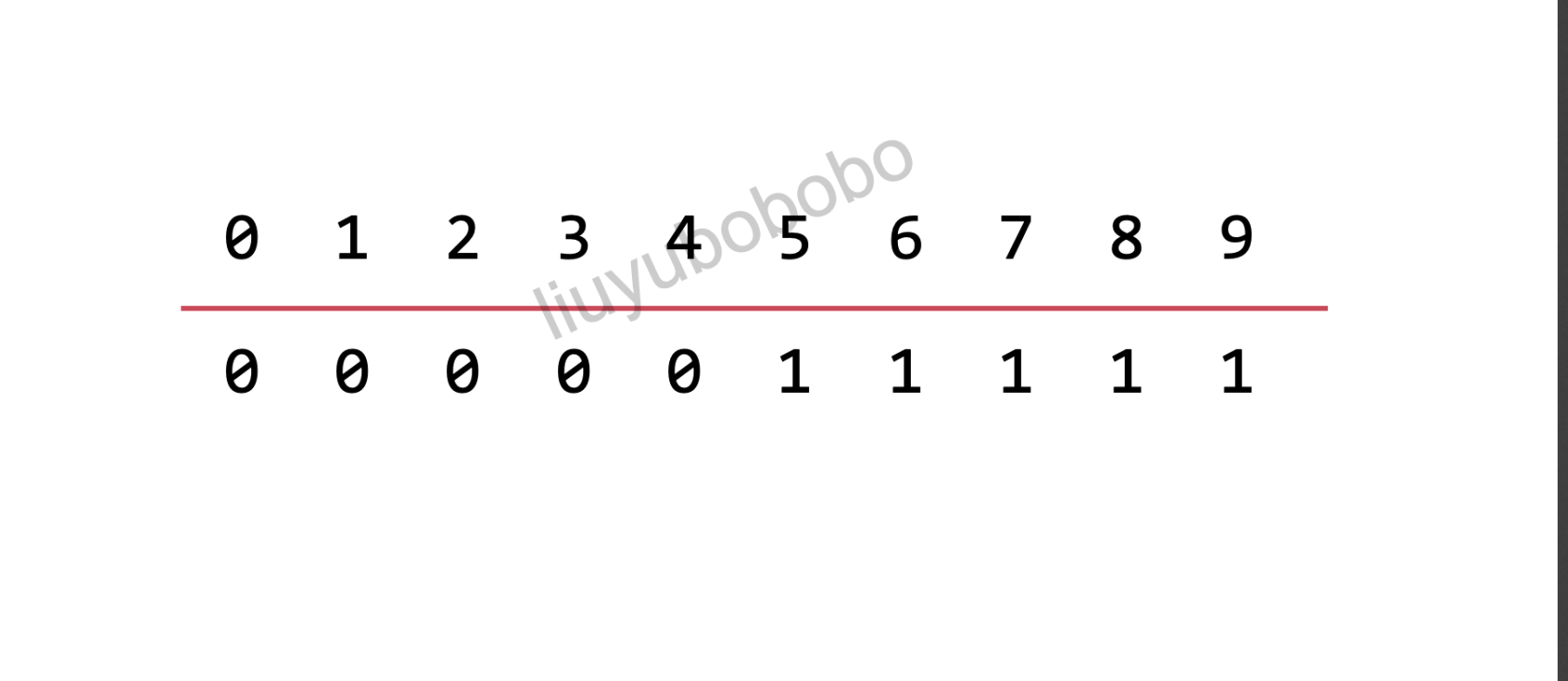
并查集的基本数据表示
难点分析:横向上的数值其实是对应横线下数据的在数组中的索引值,也就是说横线下是一个真正的数组,而横线上则是数组对应的索引,在这里我们是用索引当作元素,用数组数据值的异同来表示元素是否连接。
横线上:用数组索引表示元素
横线下:表示连接情况(值为0的表示在一个集合即连接)
所以0-4在同一个集合,5-9在同一个集合:
代码实现
下面我们来介绍并查集的主要操作: 我们先实现一个并查集:
#include <iostream>
#include <cassert>
using namespace std;
// 我们的第一版Union-Find
namespace UF1 {
class UnionFind {
private:
int *id; // 第一版Union-Find本质就是一个数组
int count; // 数据个数
public:
// 构造函数
UnionFind(int n) {
count = n;
id = new int[n];
// 初始化, 每一个id[i]指向自己, 没有合并的元素,每一个数都是一个集合
for (int i = 0; i < n; i++)
id[i] = i;
}
// 析构函数
~UnionFind() {
delete[] id;
}
- find的实现:(查询元素所在的集合编号,直接返回数组值,O(1) 的时间复杂度。)
// 查找过程, 查找元素p所对应的集合编号
int find(int p) {
assert(p >= 0 && p < count);
return id[p];
}
- isConnected的实现:
// 查看元素p和元素q是否所属一个集合
// O(1)复杂度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
- union的实现:(合并元素 p 和元素 q 所属的集合, 合并过程需要遍历一遍所有元素, 再将两个元素的所属集合编号合并,这个过程是 O(n) 复杂度。)
// 合并元素p和元素q所属的集合
// O(n) 复杂度
void unionElements(int p, int q) { //union在c++中是一个关键字,所以这里用 unionElements
int pID = find(p);
int qID = find(q);
if (pID == qID)
return;
// 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并
for (int i = 0; i < count; i++)
if (id[i] == pID)
id[i] = qID;
}
并查集的另一种实现思路(优化)
介绍
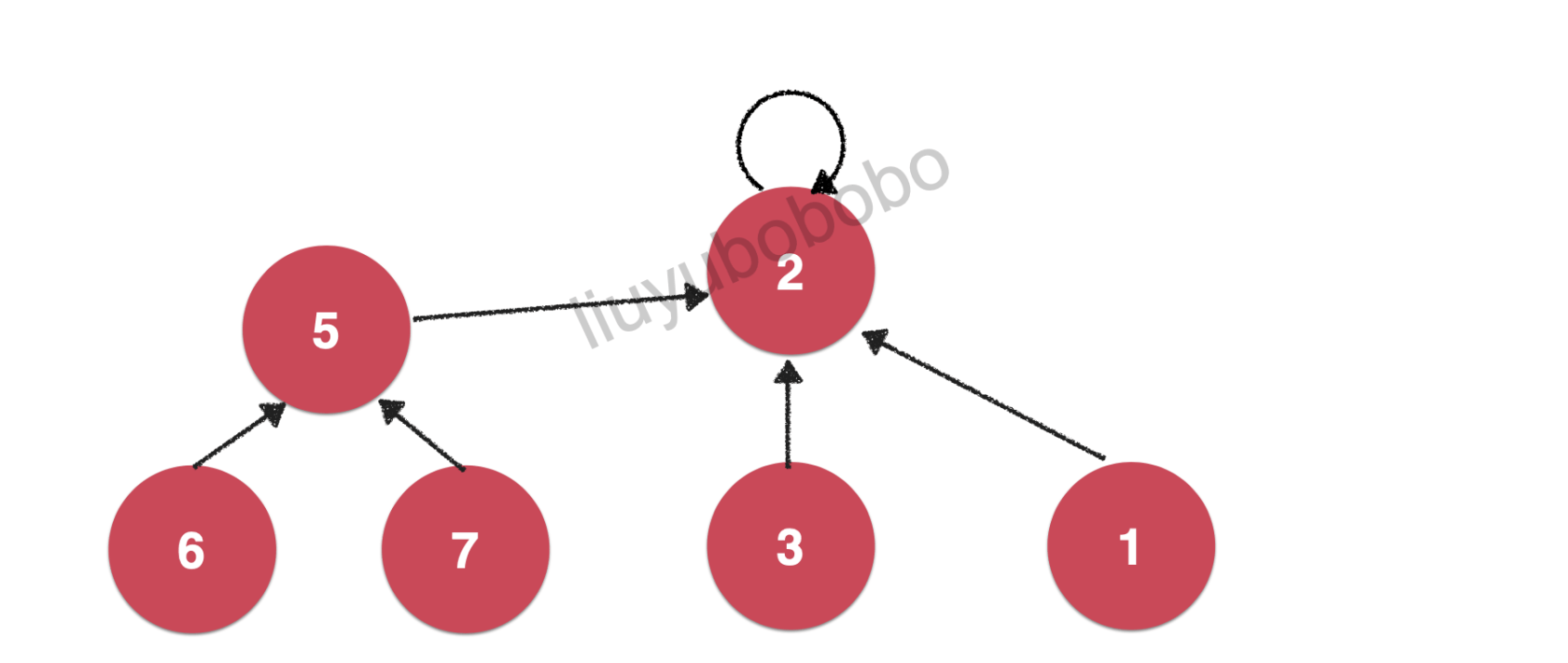
在并查集的Union( ) 中使用指针,将每一个元素看作是一个节点,并将每一个节点都指向一个节点(可以是其他节点或节点本身)即Quick Union;使用这种方法在后续可以更好的对并查集进行优化。
Union的表示方法及逻辑
在Quick Find下的union时间复杂度为( O(n) )
将每一个元素看作是一个节点,如下图:
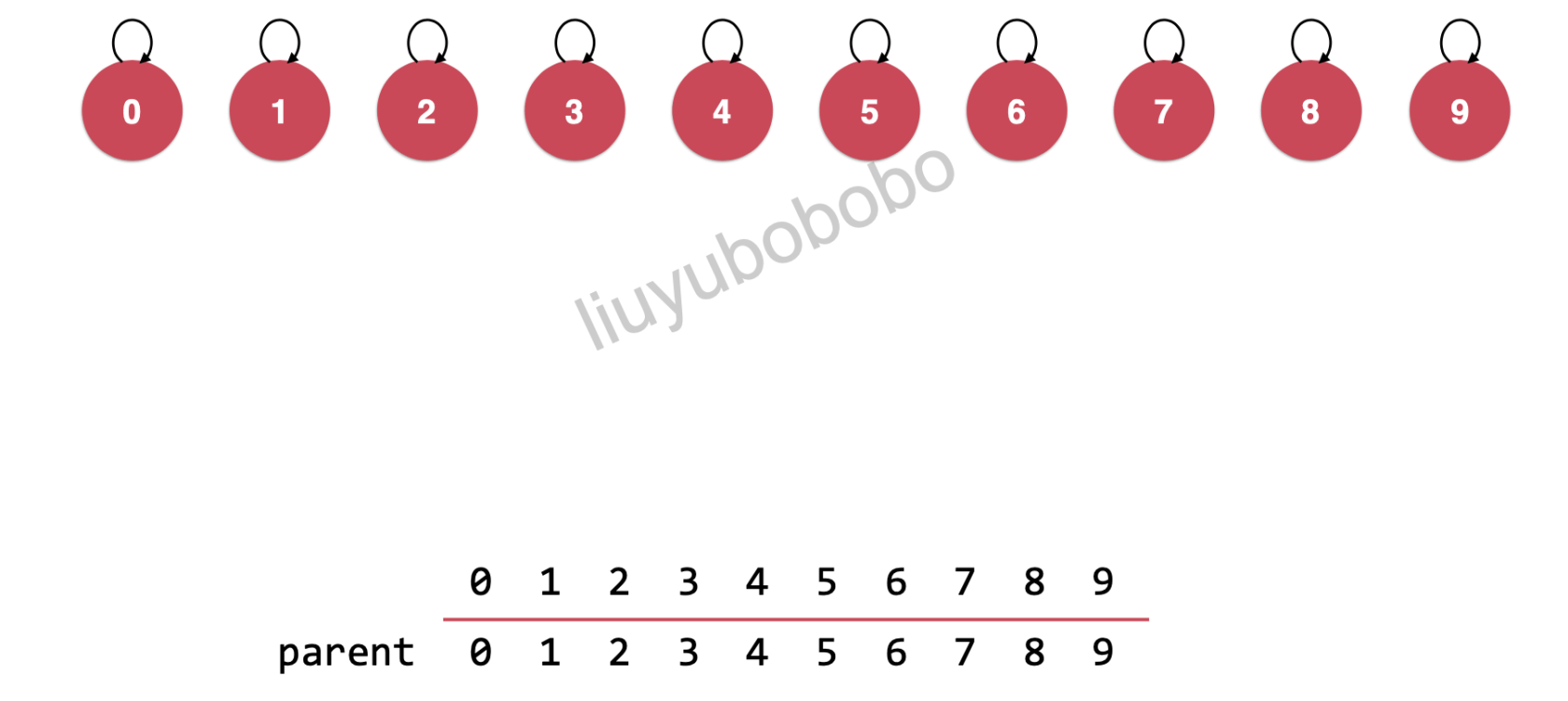
初始化一样,每一个元素是一个集合
并且每一个元素指向自己
下面我们将4,3连接( union(4, 3) )
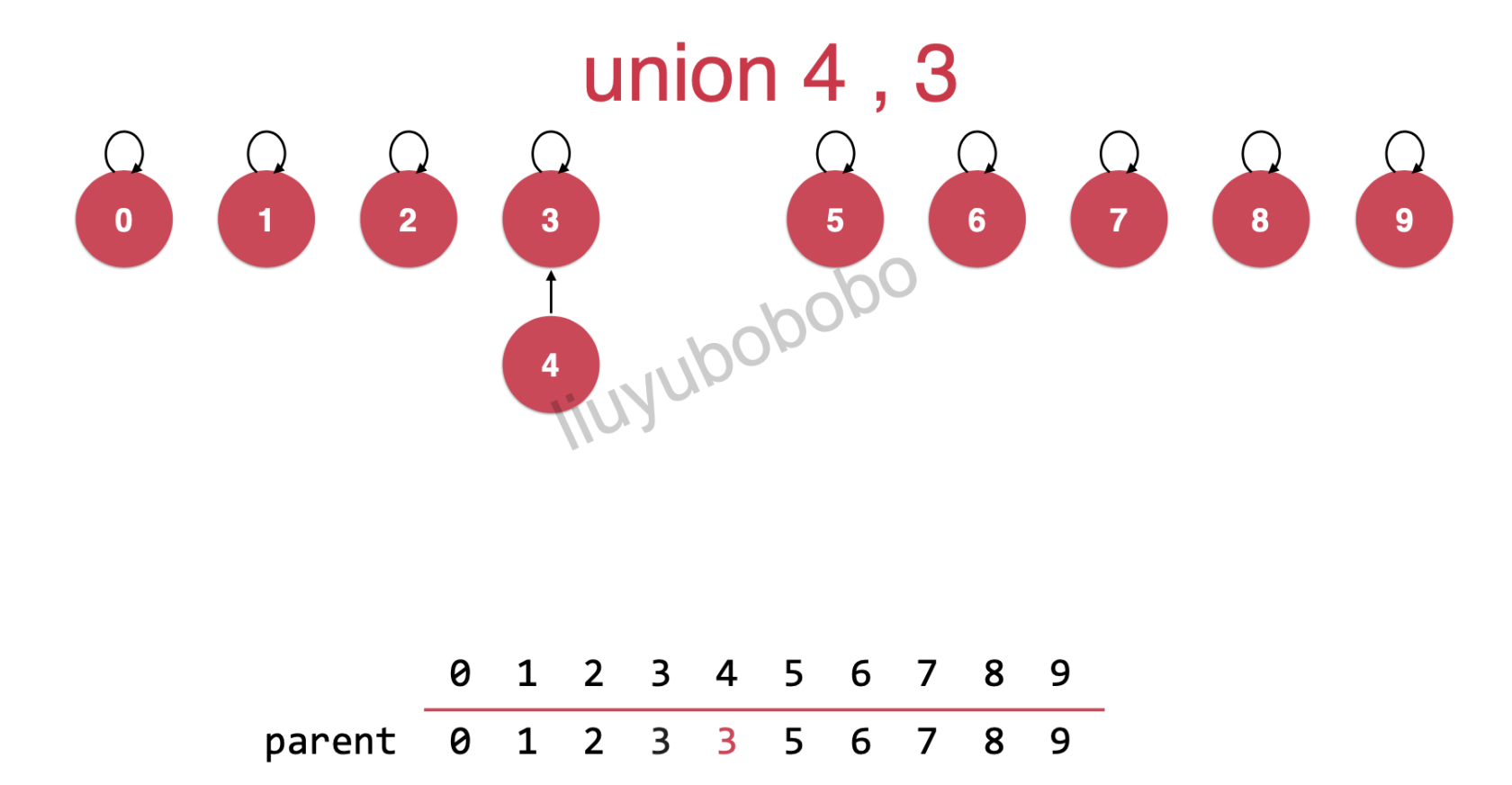
再继续:将3,和8连接(union(3, 8) )
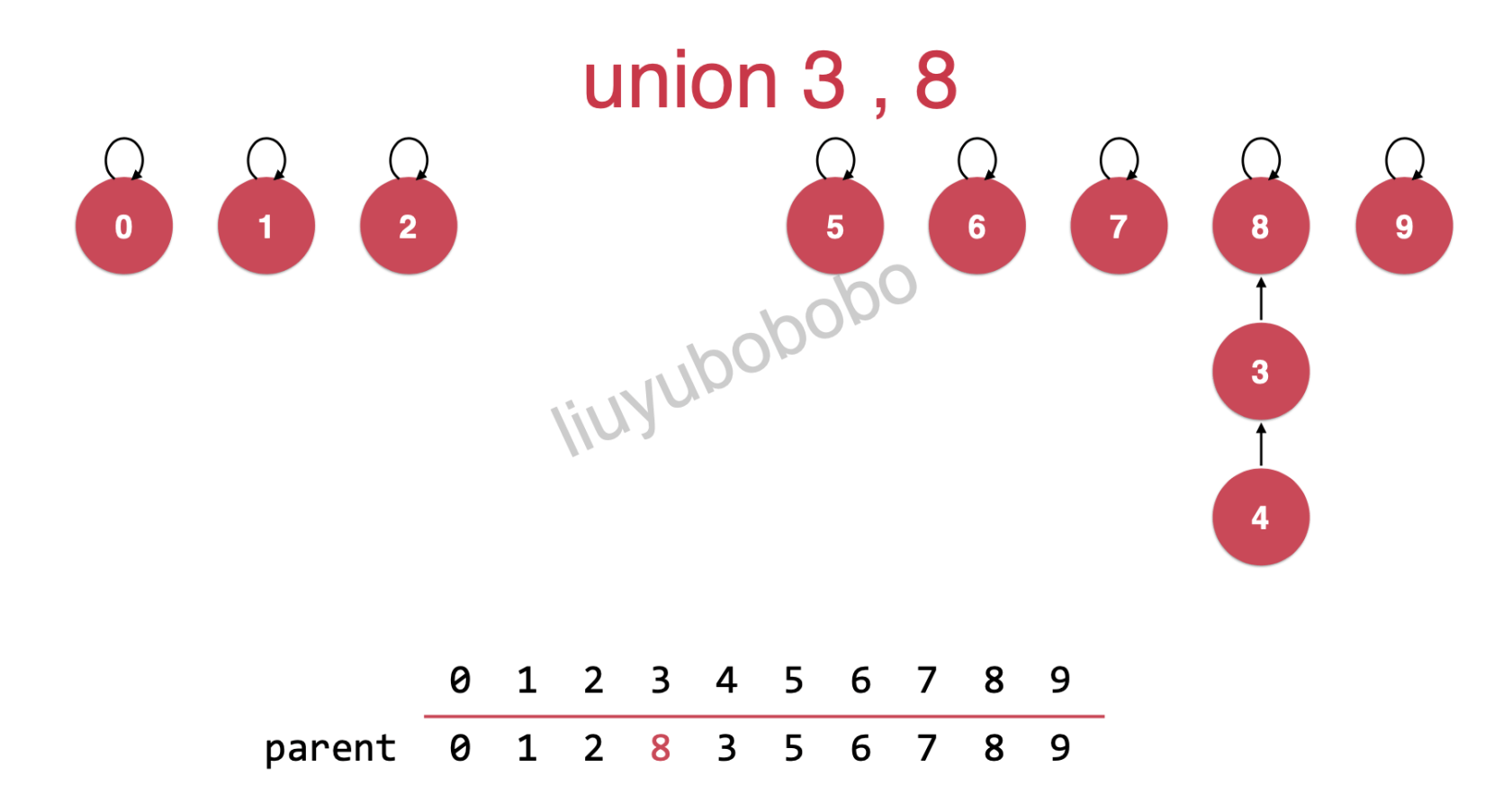
将6,5进行连接( union(6, 5) )
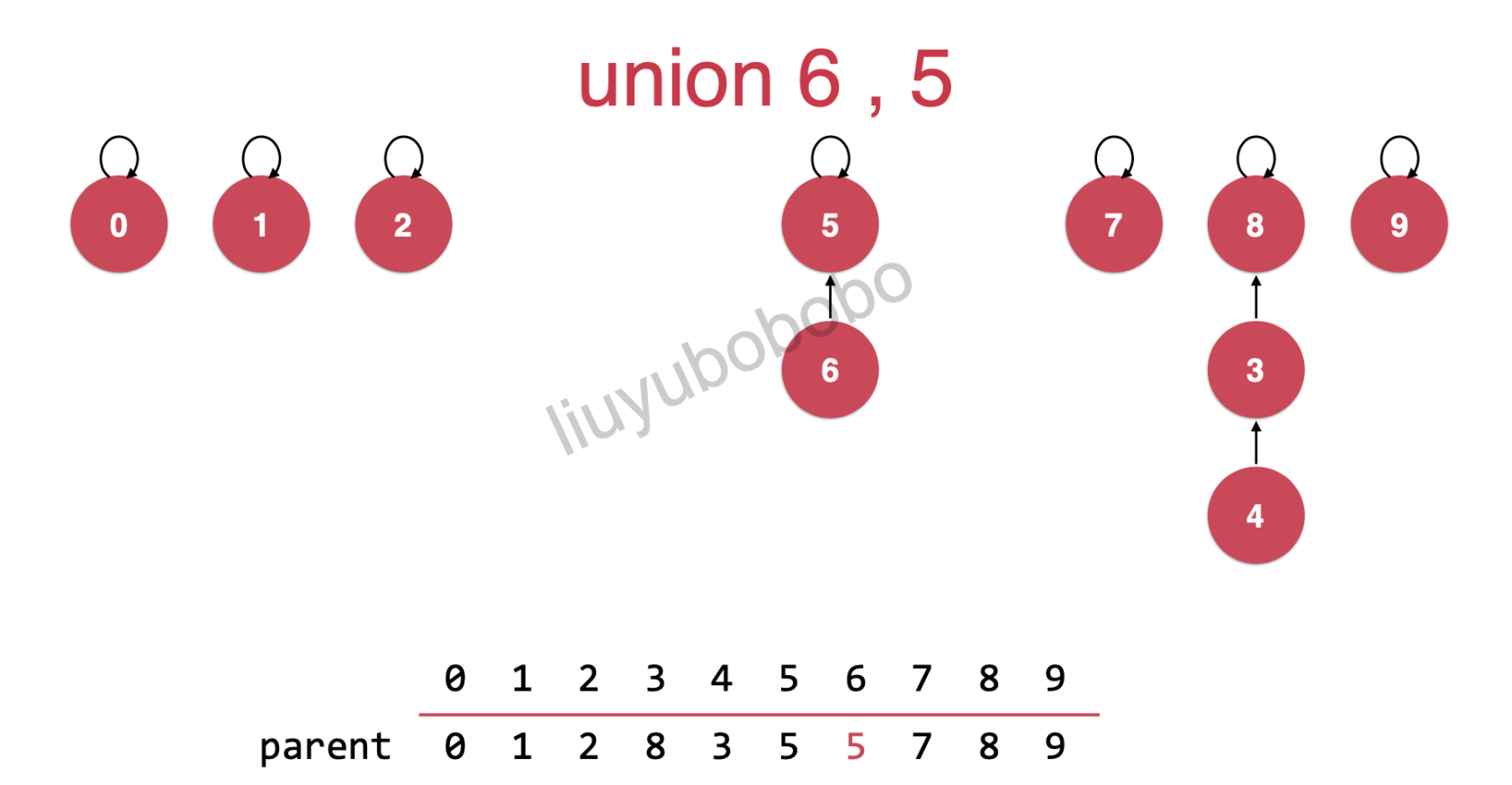
这里注意:我们将9,4连接( union(9, 4) )
我们是将9指向8节点(这样更优化),在逻辑上就是9,和4连接上了
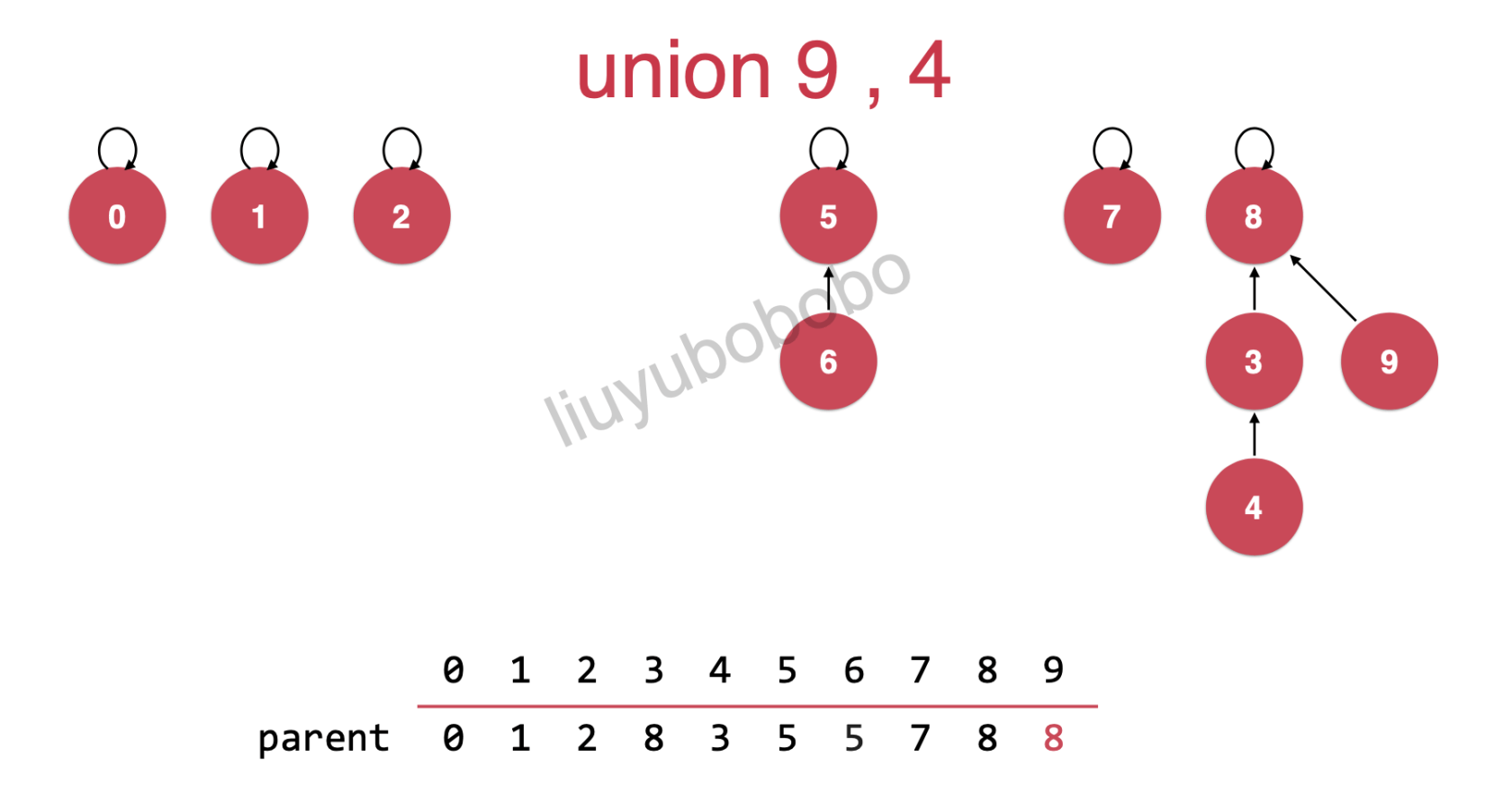
再看这里,同样的逻辑,将其中一方的根节点指向另一个的根节点
连接6,2 ( union(6, 2) )
 连接后:
连接后:
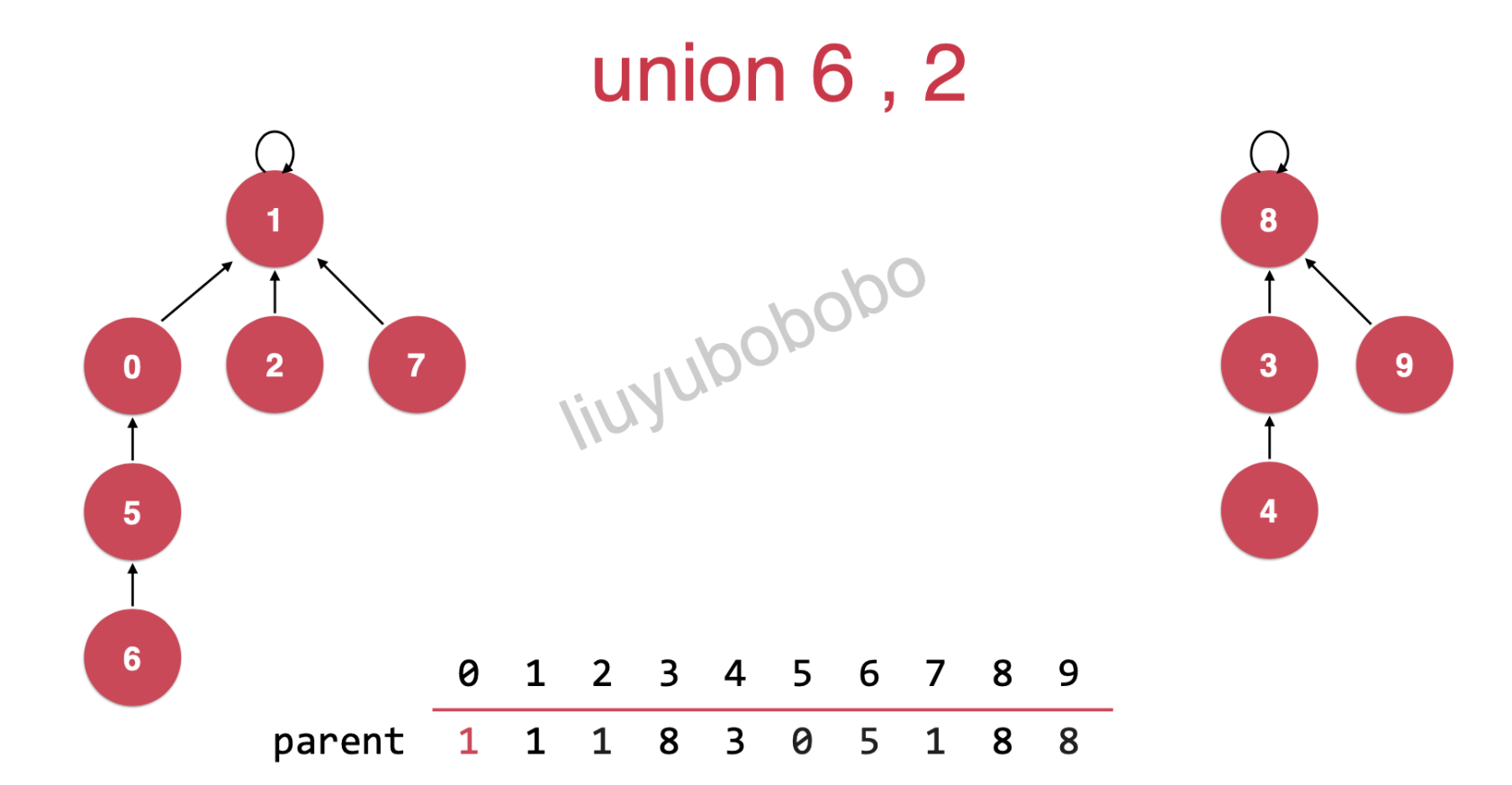
优化后的表示方法及逻辑就是这样。
代码实现
我先看union部分:
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionElments(int p, int q) { //union在c++中是关键字
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
parent[pRoot] = qRoot;
}
下面是完整代码:
#include<cassert>
using namespace std;
namespace UF2 {
class UnionFind2 {
private:
// 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树
// parent[i]表示第i个元素所指向的父节点
int *parent;
int count; //数据个数
public:
UnionFind2(int count) {
parent = new int[count];
this->count = count;
//初始化
for (int i = 0; i < count; i++) {
parent[i] = i;
}
}
//析构函数
~UnionFind2() {
delete parent;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
int find(int p) {
assert(p >= 0 && p <= count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while (p != parent[p])
p = parent[p];
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionElments(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
parent[pRoot] = qRoot;
}
};
}
并查集基于size的优化
介绍及逻辑
介绍
在上一小节我们使用指针的方法将每一个元素都看作是一个节点,并且是节点指向另一个节点(包括自己),在这一小节中我们将在此基础上进行优化。 先来介绍一下什么是"size" size : size[i] 是指用来记录以i为根节点的树所包含的节点个数,本质是一个数组
逻辑
先来看看下面的图片: 现在需要将4,2连接起来,该怎么连?
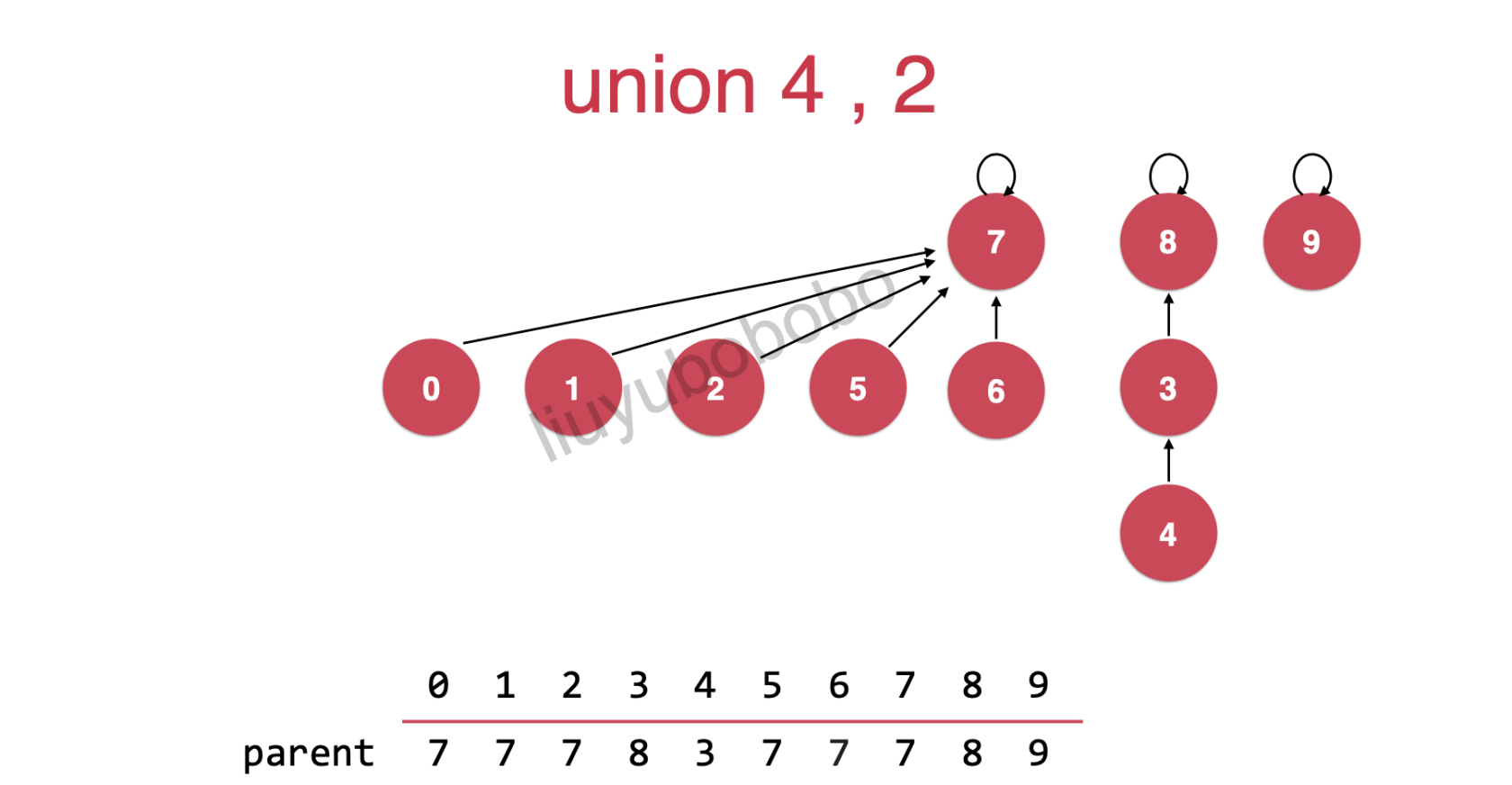
方法一:如下图
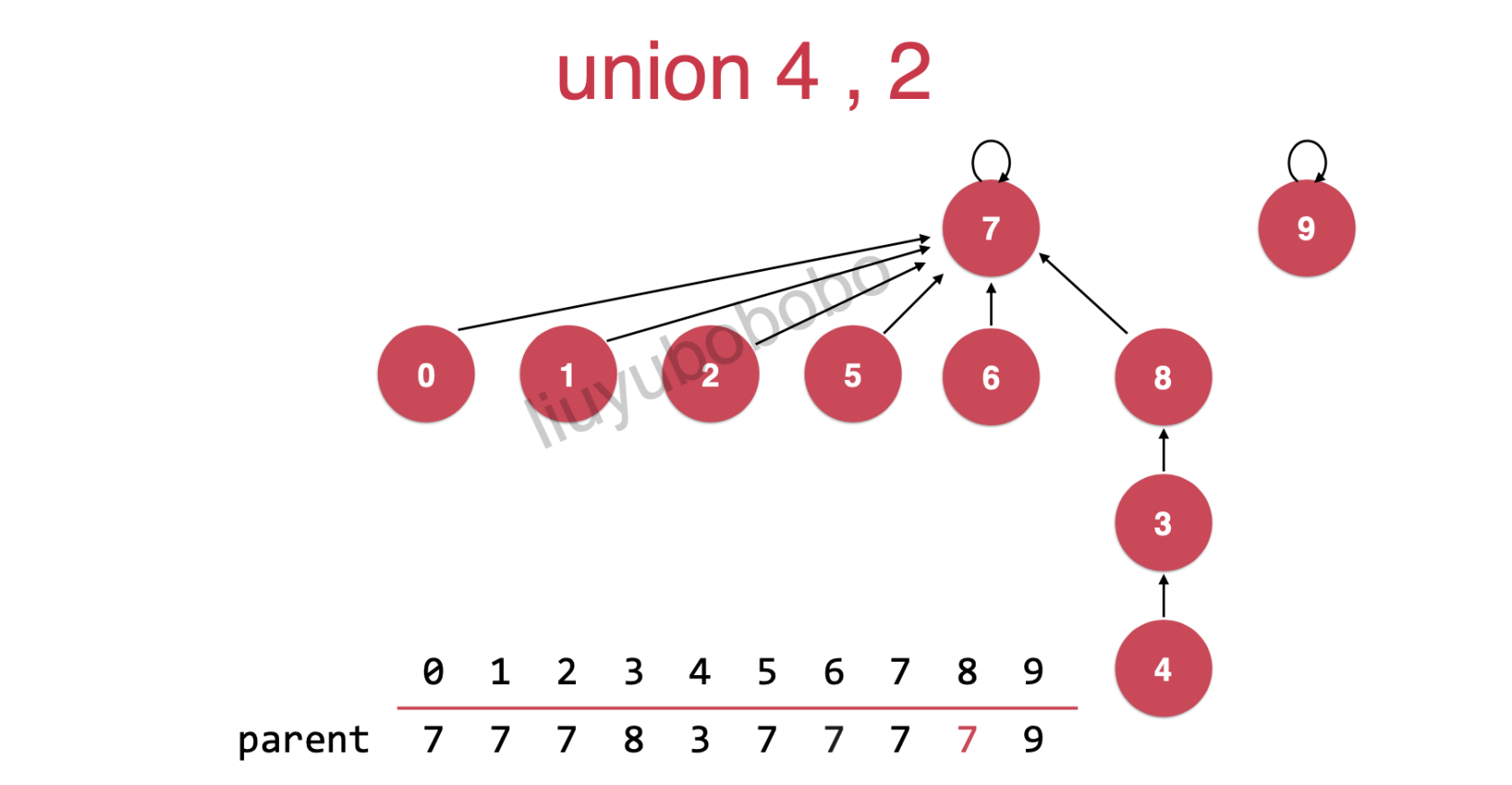
方法二:如下图
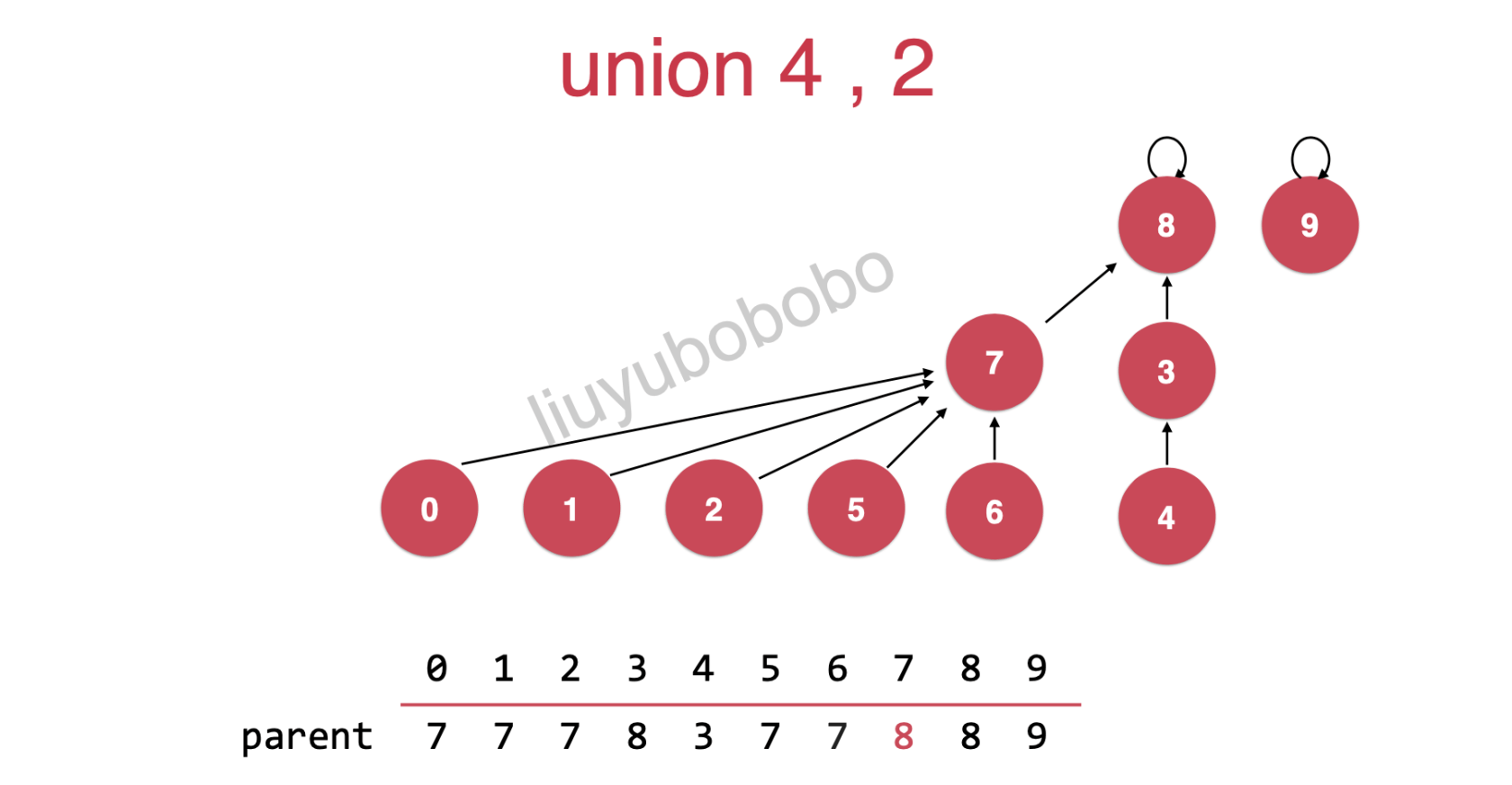
很容易看出方法二更优,树的高度越高,对计算机的消耗也会越大,所以很明显方法二是有3层,而方法一有4层(一旦有大量的数据时,性能差别就会明显); 所以我们使用size数组,就是在维护方法二。
代码实现
#include<cassert>
using namespace std;
namespace UF3 {
class UnionFind2 {
private:
// 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树
// parent[i]表示第i个元素所指向的父节点
int *parent;
int *size; //size用来记录节点的个数
int count; //数据个数
public:
UnionFind2(int count) {
parent = new int[count];
size = new int[count];
this->count = count;
//初始化
for (int i = 0; i < count; i++) {
parent[i] = i;
size[i] = 1;
}
}
//析构函数
~UnionFind2() {
delete parent;
delete size;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
int find(int p) {
assert(p >= 0 && p <= count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while (p != parent[p])
p = parent[p];
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
下面是size的核心:
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionElments(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
// 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if(size[pRoot] < size[qRoot]) {
parent[pRoot] = qRoot;
size[qRoot] = +size[pRoot];
}
else { //size[pRoot] >= size[qRoot]
parent[qRoot] = pRoot;
size[pRoot] = +size[qRoot];
}
}
};
}
并查集基于rank的优化
介绍
背景
前面将到并查集基于size的优化,其实仔细想想,还是有可以优化的地方;size[i]是指以i为根节点树的节点数;是将节点数量多的树的根节点向节点数好的树的根节点连接,在一般情况下是得到了优化,但是这里就存在问题了,当出现:节点数多的树它的高度非常高的时候,size的优化方式就不太高效了。
rank
rank[i]:是用来记录以i为根节点的树的高度(树的层数),其本质是数组。
逻辑
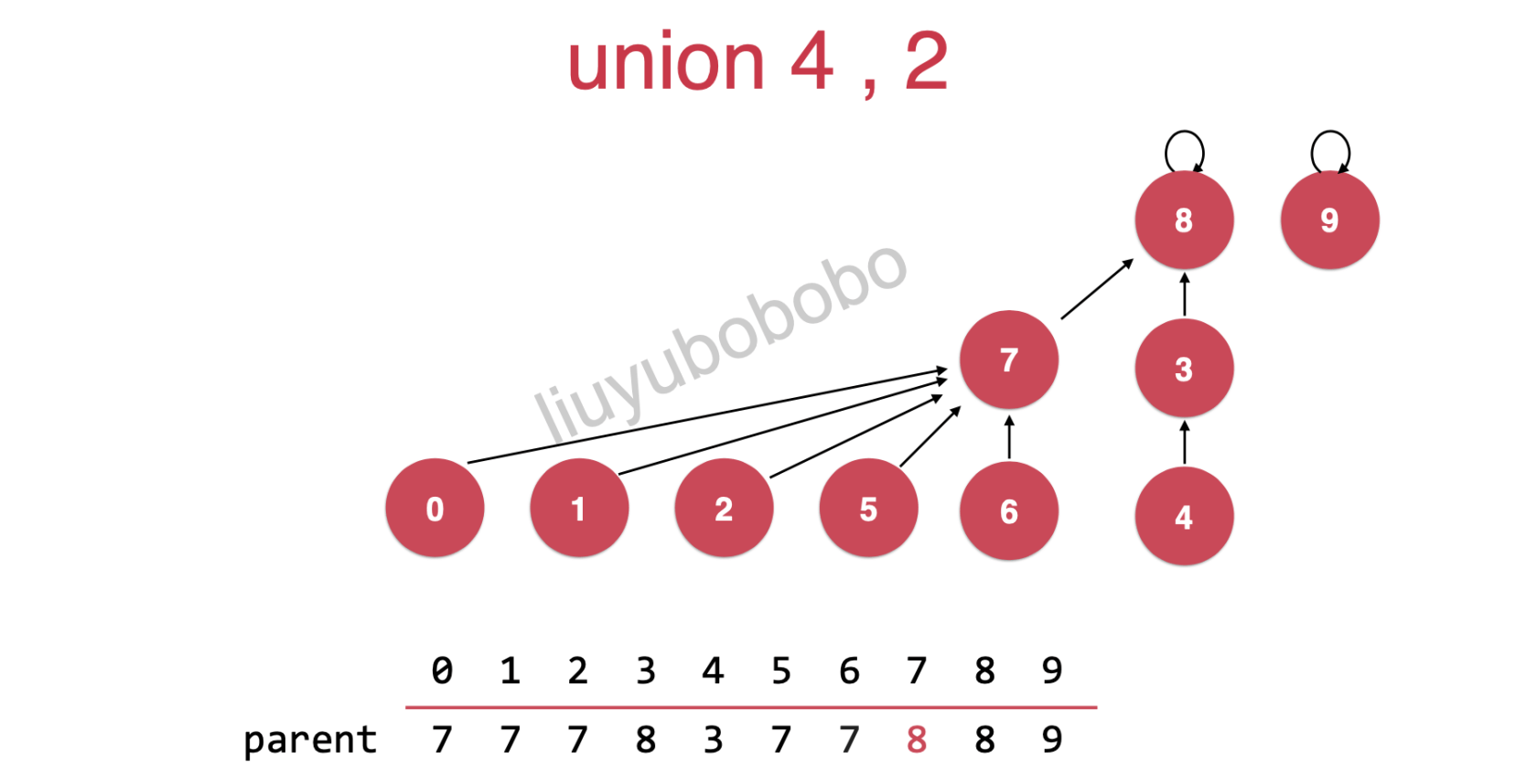
并查集本质是树,当树的高度(层数)越高在对数的操作其复杂度会越高,rank的目的就是降低在并(union)过程中并查集的高度;在并(union)过程中使用rank来记录合并的两棵树的高度,将rank值小的树的根节点指向rank值大的根节点。如下图:
连接2,4( union(4,2) )
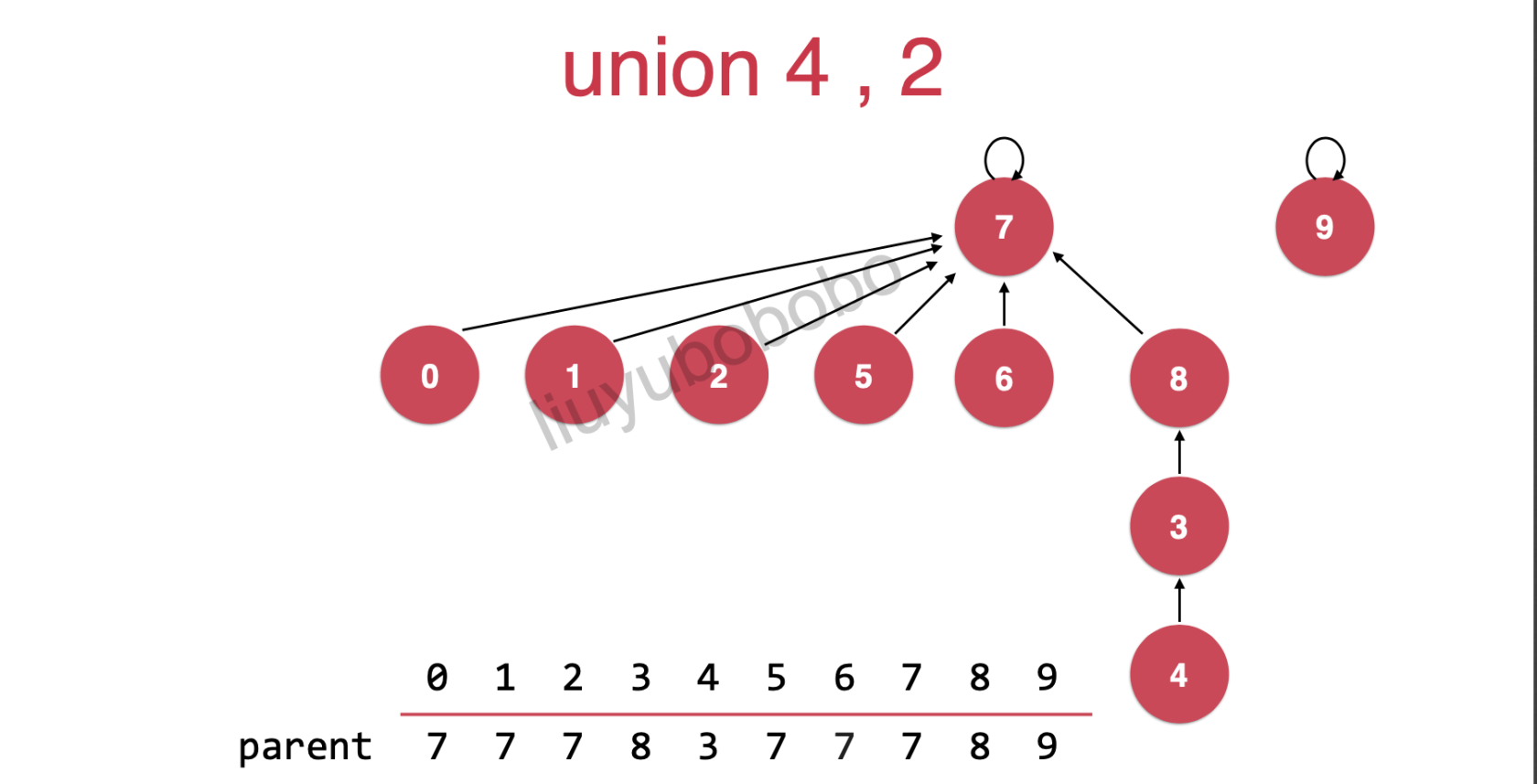
方法一:
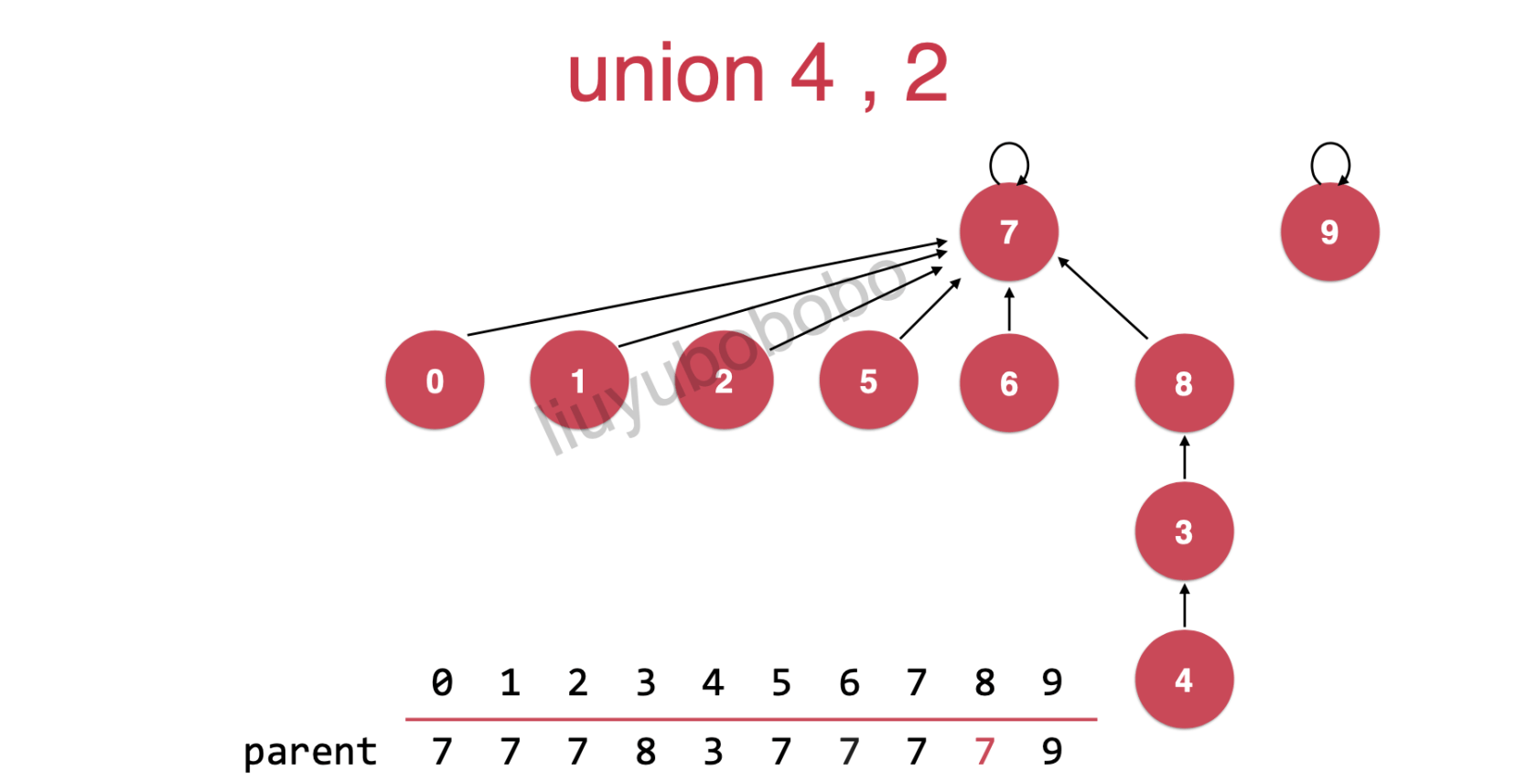
方法二:
很明显方法二比方法一更优
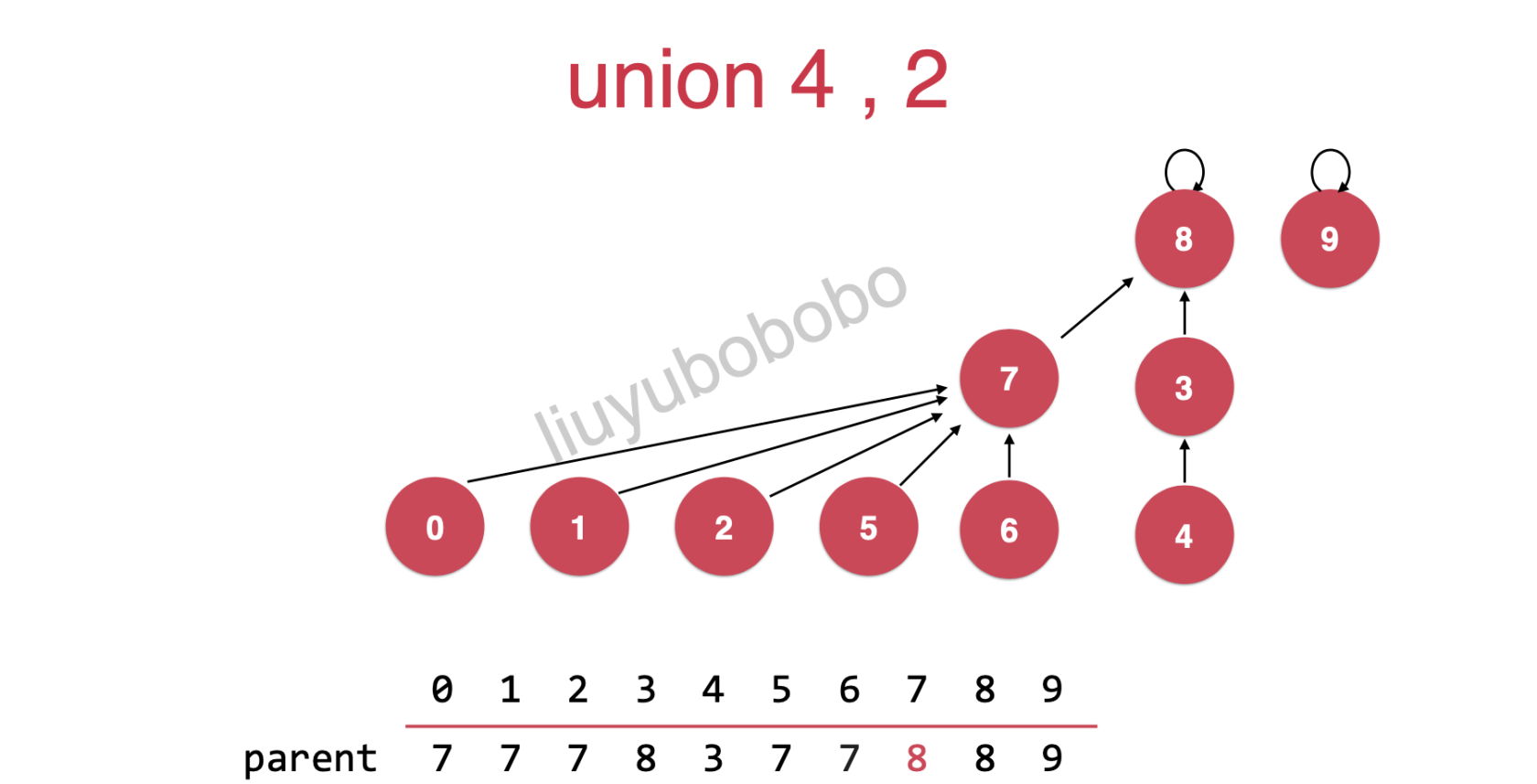
方法二:正是基于rank的优化
具体逻辑如下:
rank[7] = 2
rank[8] = 3
此时只需要将rank[7]树的根节点指向rank[8]树的节点
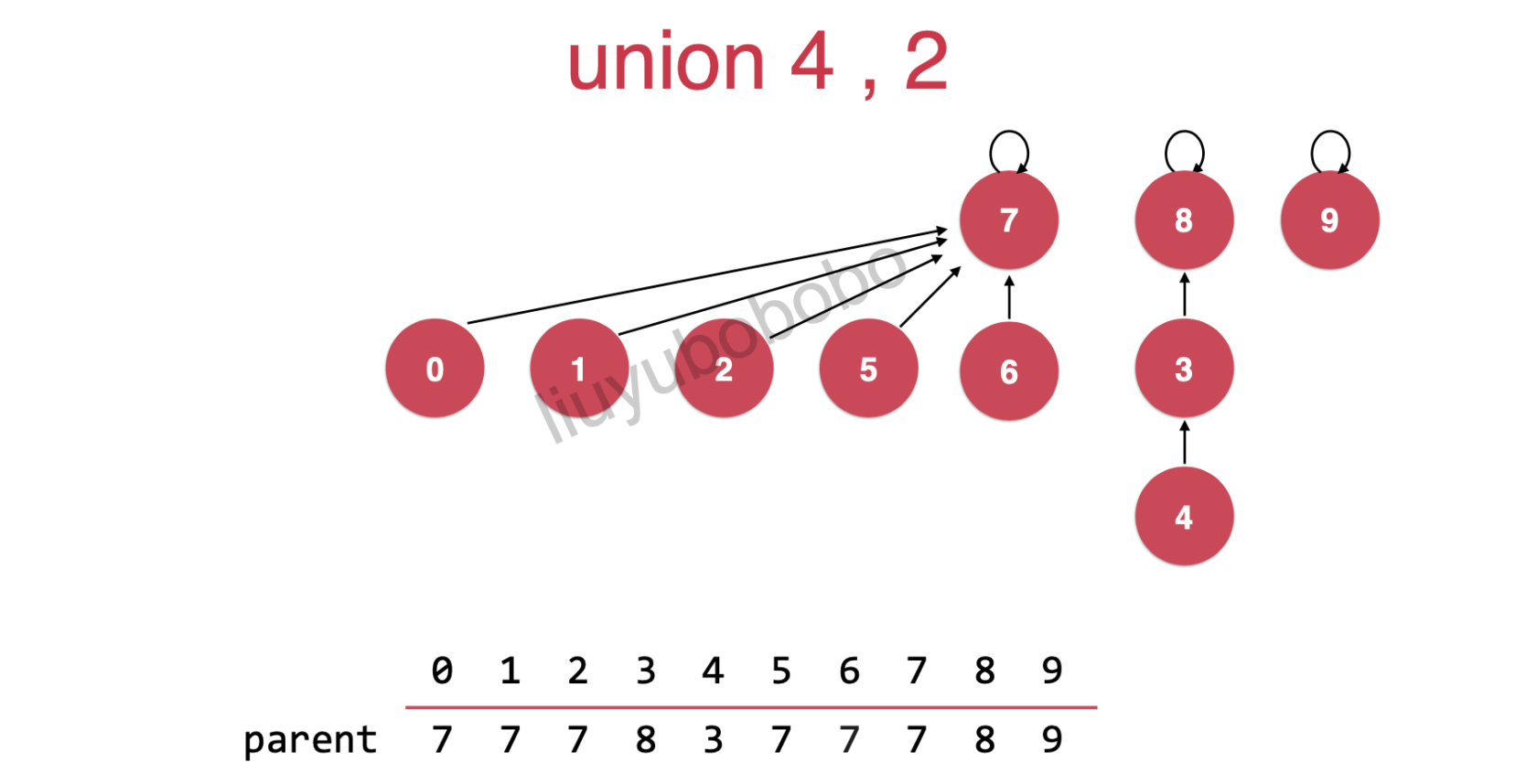
合并后,如下:
此时整个并查集rank[8] = 3,高度不变
代码实现
#include<cassert>
using namespace std;
namespace UF4 {
class UnionFind4 {
private:
// 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树
// parent[i]表示第i个元素所指向的父节点
int *parent;
int *rank;
int count; //数据个数
public:
UnionFind4(int count) {
parent = new int[count];
rank = new int[count];
this->count = count;
//初始化
for (int i = 0; i < count; i++) {
parent[i] = i;
}
}
//析构函数
~UnionFind4() {
delete parent;
delete rank;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
int find(int p) {
assert(p >= 0 && p <= count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while (p != parent[p])
p = parent[p];
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
rank核心部分:
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionElments(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
if (rank[pRoot] > rank[qRoot]) {
parent[pRoot] = qRoot;
}
else if (rank[pRoot] < rank[qRoot]) {
parent[qRoot] = pRoot;
}
else {//rank[pRoot] == rank[qRoot]
parent[qRoot] = pRoot;
rank[qRoot] = +1;
}
}
};
}
并查集的路径压缩
介绍
并查集里的 find 函数里可以进行路径压缩,是为了更快速的查找一个点的根节点。对于一个集合树来说,它的根节点下面可以依附着许多的节点,因此,我们可以尝试在 find 的过程中,从底向上,如果此时访问的节点不是根节点的话,那么我们可以把这个节点尽量的往上挪一挪,减少数的层数,这个过程就叫做路径压缩。 通俗的说就是把find过程中“查找节点”的路劲变短,让find能更快的更高效。
逻辑
例如:find( 4 )
我们需要从下到上的找到根节点,当这条路劲很长,逻辑上花费的时间就会多一些
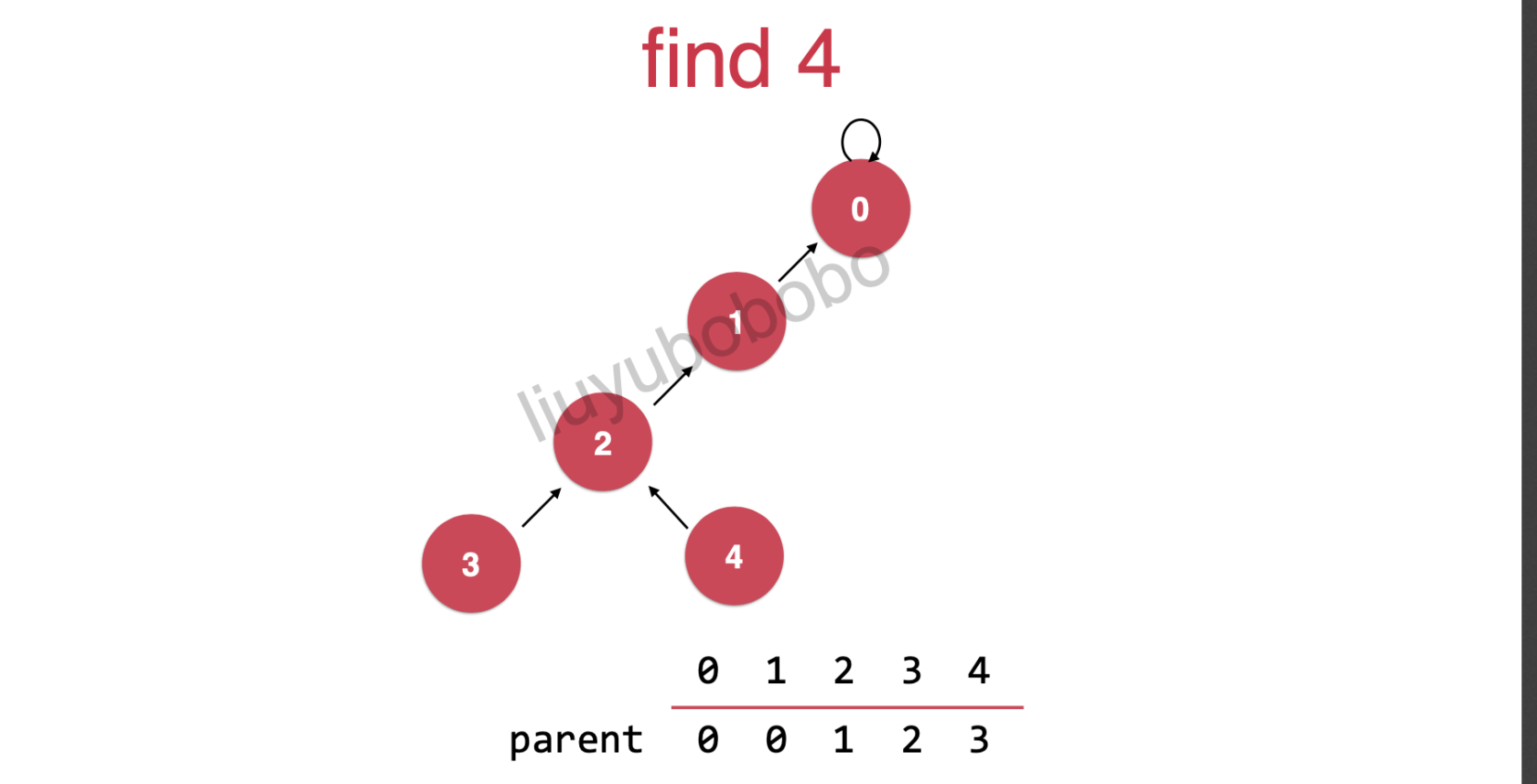
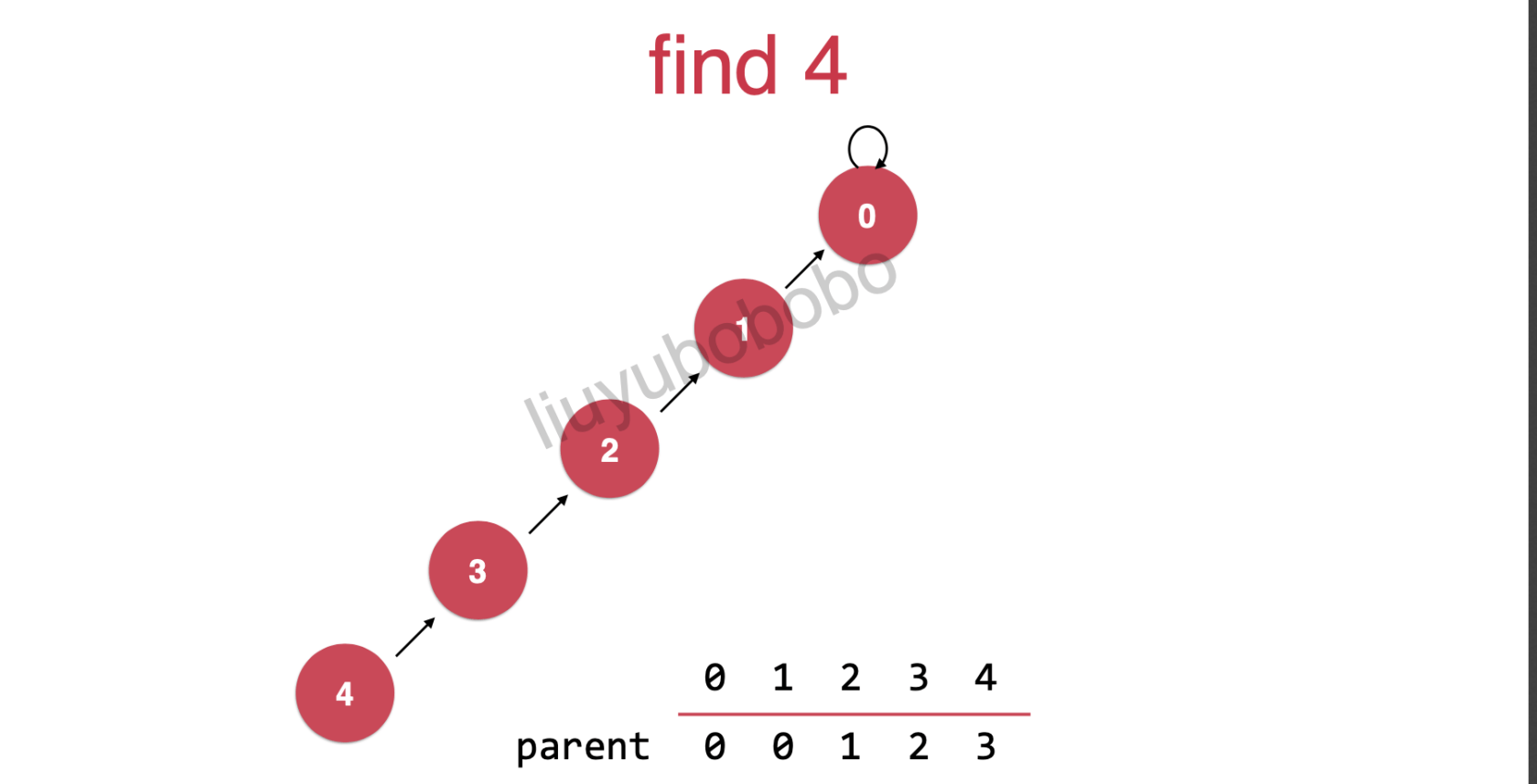 在路劲压缩的这个过程需要不断去查询自己的父亲节点, 直到到达根节点,而根节点的特点: parent[p] == p
不断的将节点4网上挪一挪使用:
parent[p] = parent[parent[p]];
在路劲压缩的这个过程需要不断去查询自己的父亲节点, 直到到达根节点,而根节点的特点: parent[p] == p
不断的将节点4网上挪一挪使用:
parent[p] = parent[parent[p]];
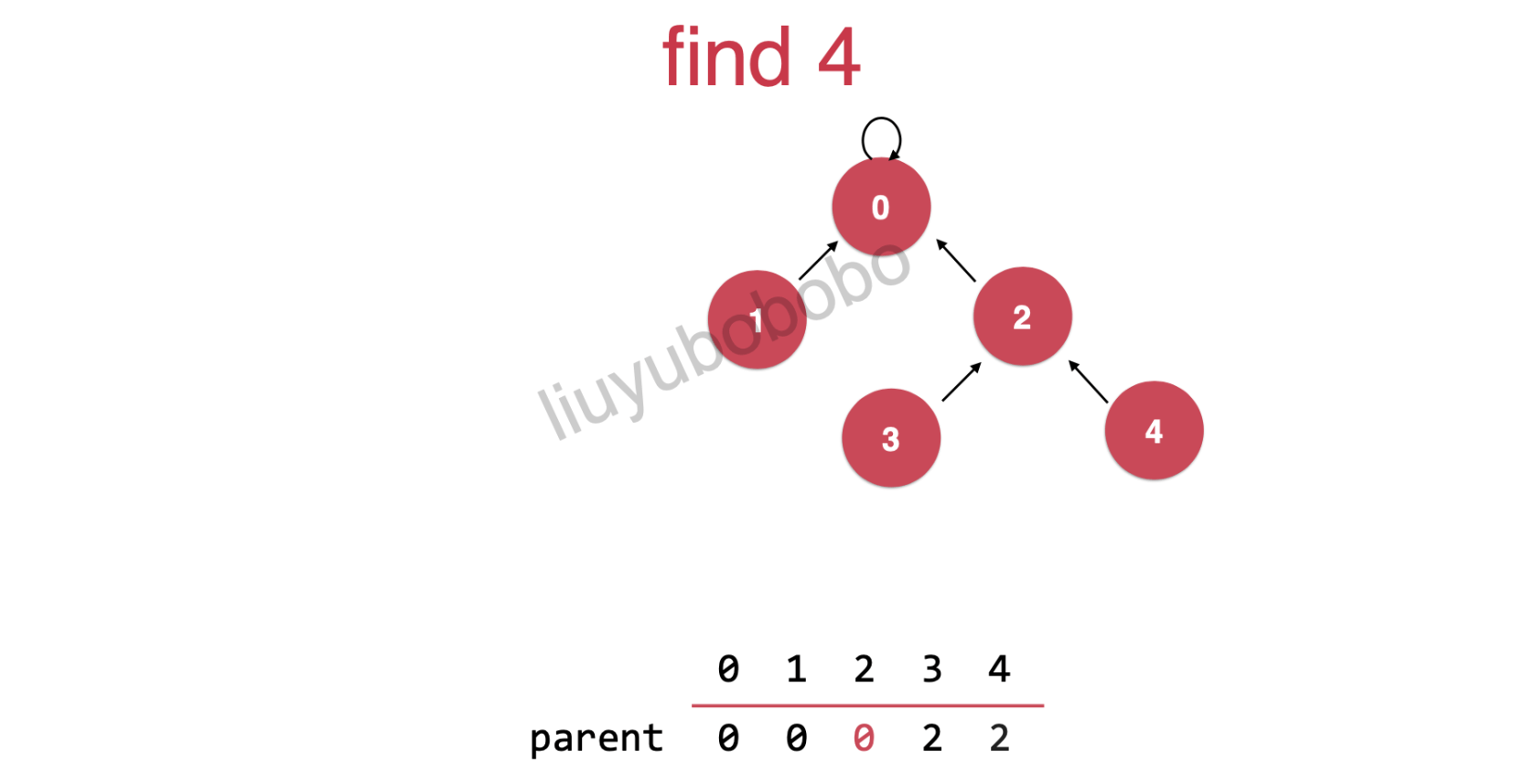
 最后就完成了路径压缩:
最后就完成了路径压缩:
代码实现
#include<cassert>
using namespace std;
namespace UF4 {
class UnionFind5 {
private:
// 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树
// parent[i]表示第i个元素所指向的父节点
int *parent;
int *rank;
int count; //数据个数
public:
UnionFind5(int count) {
parent = new int[count];
rank = new int[count];
this->count = count;
//初始化
for (int i = 0; i < count; i++) {
parent[i] = i;
}
}
~UnionFind5() {
delete parent;
delete rank;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
int find(int p) {
assert(p >= 0 && p <= count);
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while (p != parent[p])
parent[p] = parent[parent[p]];
p = parent[p];
return p;
//递归算法
// if (p != parent[p])
// parent[p] = find(p);
// return parent[p];
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
bool isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
void unionElments(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
if (rank[pRoot] > rank[qRoot]) {
parent[pRoot] = qRoot;
}
else if (rank[pRoot] < rank[qRoot]) {
parent[qRoot] = pRoot;
}
else {//rank[pRoot] == rank[qRoot]
parent[qRoot] = pRoot;
rank[qRoot] = +1;
}
}
};
}
(图片来源:慕课网课程《算法与数据结构》)